



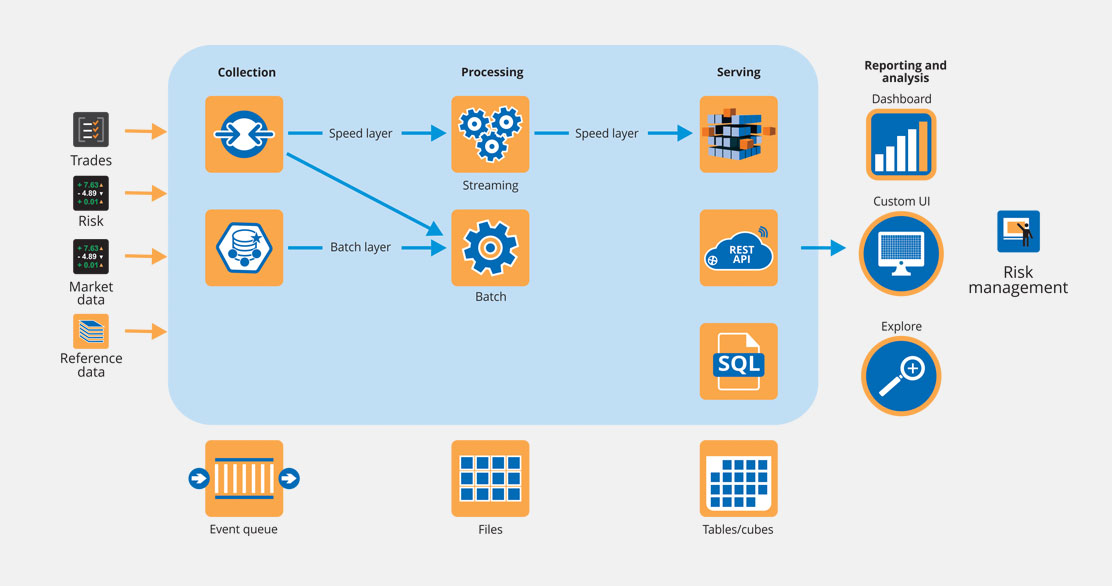
Platform Features
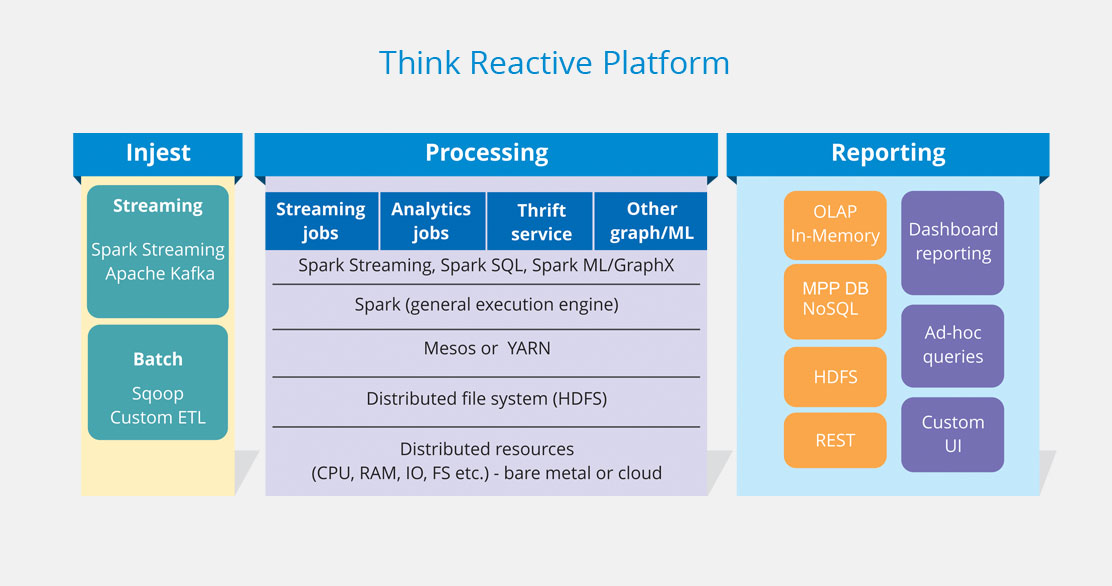
Data injest
Streaming and batch, using Flume, Kafka and Sqoop, all standard sources and sinks supported out of the box
Data parsing
Handle all formats, structured, unstructured, plus add native support for custom ones
Polygot persistence
Choose the best storage for your data from HDFS, NoSQL stores and relational databases, process and join across data sources transparently.
Bare metal or cloud ready
Analytics features
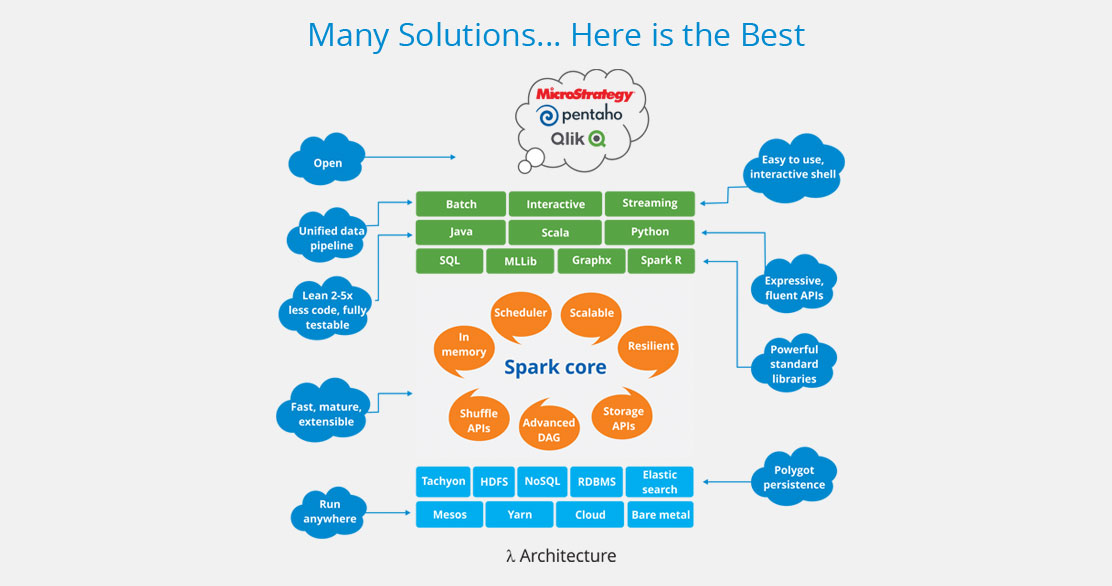
SQL, ML, graph processing, Scala, Java, Python and R
Ad-hoc query interface
Structure Query Language (SQL)
Open platform
Integrate with your visualisation, BI tools, databases, analytics libraries
Efficient cluster management
High utilisation, share resources, isolation

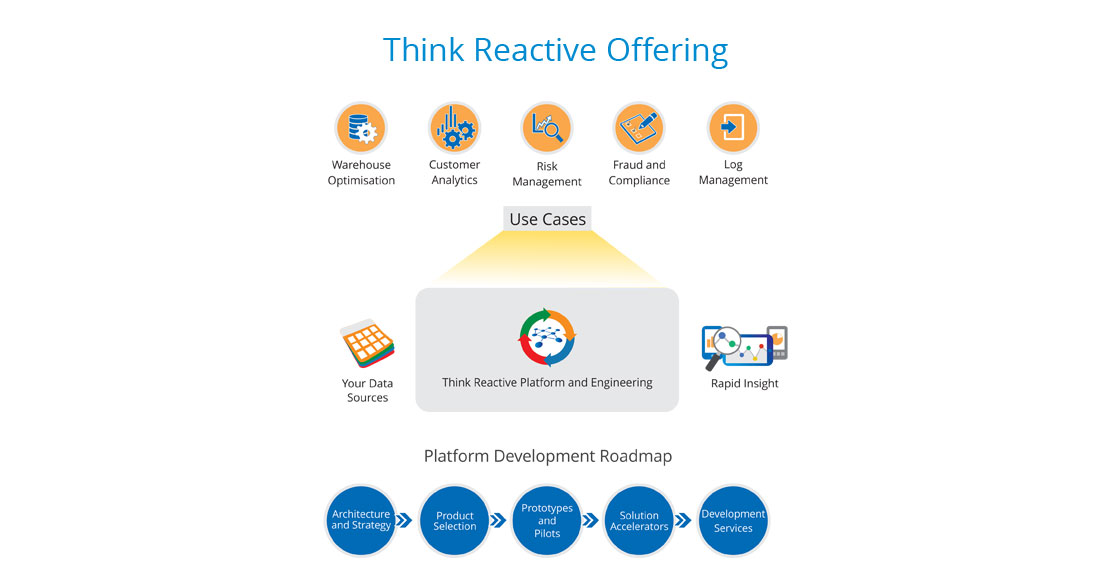
About us
- Think Reactive provides a responsive, resilient, elastic, ready-to-go data analytics platform.
- The team has a broad base of solution design and implementation experience. This includes database design, reactive, scalable & distributed applications, Big Data stack, in-memory data grids, caching and grid computing solutions, web development and middleware.
- Open-source enthusiasts with hands-on experience in solving real “Big Data” challenges.
- We are early adopters of Spark and Hadoop. We have 3 years of expertise in Scala, 15+ years in JVM, functional, actor based programming and the reactive paradigm.
- We have built and patched Hadoop, Hive and Spark. Experts in Flume, Sqoop, Spark SQL, Spark Streaming, Docker, Mesos and cloud deployments.
- We have a proven track record of high-quality delivery at Deutsche Bank, Bank of America, Dresdner KB, IG Index and Aleri.
- Active in meetups, forums and contributors to several open source projects.
- We are market risk subject matter experts.
Why us
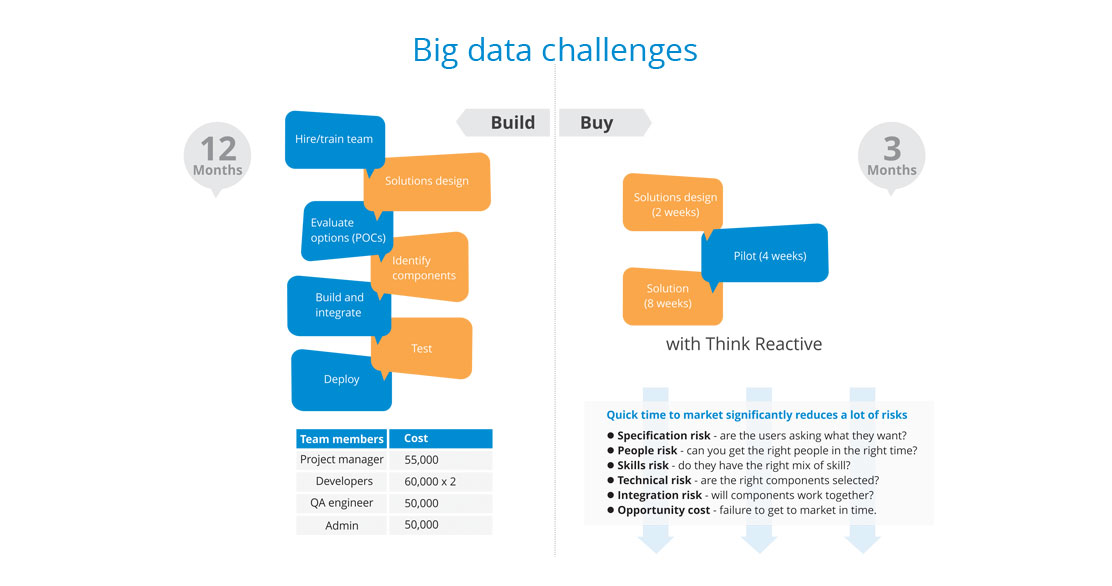
- Experience with real-world projects into production, not just PoCs and pilots
- Fully tested, pre-integrated and hardened platform
- Expertise to build custom extensions to Hadoop, adapters for custom sources and sinks, custom input and output format for your data
- Not just Hadoop, but wider experience, select best component for user needs
- Spark specialists
- Vendor-neutral
Projects
Portfolio Stress Testing
Requirements
- Increased demand internally and from the regulators to run bank-wide portfolio stress tests (100x)
- Trade-level position feed available (10x)
- Stringent SLAs (run, test and create new scenarios)
- Legacy system took 1 day to run a stress test and was hard to scale
- New scenario definition took 60,000 rules and 2 months to implement
- No transparency in scenario PnLs
Challenging deadlines
Challenges
- Databases hard to scale
- Complex shocking logic hard to implement
- Custom solution route was risky carried high amount of risk
Solution
- Defined new hierarchical shock and scenario definition model
- Map Reduce to provide linear scalability, spark/shark for speed
- HDFS for persistence, Hive for a SQL interface for reports and self-service analysis
- Columnar storage format and fast splittable compression
- Hive complex types to implement evolvable schemas
Benefit
- New scenario definition took 300 rules and 1 day to construct
- Time to run a scenario reduced from 1 day per scenario to 15 mins for multiple scenarios
- Integrated portfolio stress testing platform handling injest, calculation, storage, reporting, adhoc query and analysis.
- Complete transparency in all steps
- Storage requirements reduced by a 10th
- Self service platform. No IT involvement to define new scenarios, change shocking rules, intensity levels, new reports, adhoc analysis. Hive UDFs provide a DSL for users. Platform used for multiple different stress tests, CCAR, Equity, EBA, etc.
Streaming Risk Distribution and Aggregation
Requirements
- 5 billion risk measures per day from 4000 blades
- Complex downstream processing requirements – enrichments, vectorisation, etc.
- Complex optimized for the wire message formats
Trade rerun handling
Solution
- Custom Hadoop Serializer/Deserializer (SerDe) to handle message format
- Spark and Spark streaming for transformation, deduplication, enrichment, end of run workflow, validation, reporting schema generation, summary reports
- Flume JMS source, Spark Streaming sink, flume interceptors
- Reports to SAS Visual Analytics via SAS Access for Hadoop
Benefit
- No code required to parse message formats
- Adhoc query access to all source message attribute without any additional effort
- Loosely coupled with data producers, allows systems to evolve independently
- Transparency – all source message attributes available at the most granular level
- Reduced time to market
- Fully scalable injest, processing and access layers single code base for both streaming and batch layers
- Out of the box, no data loss, quick time to market
- Plugin any visualisation layer